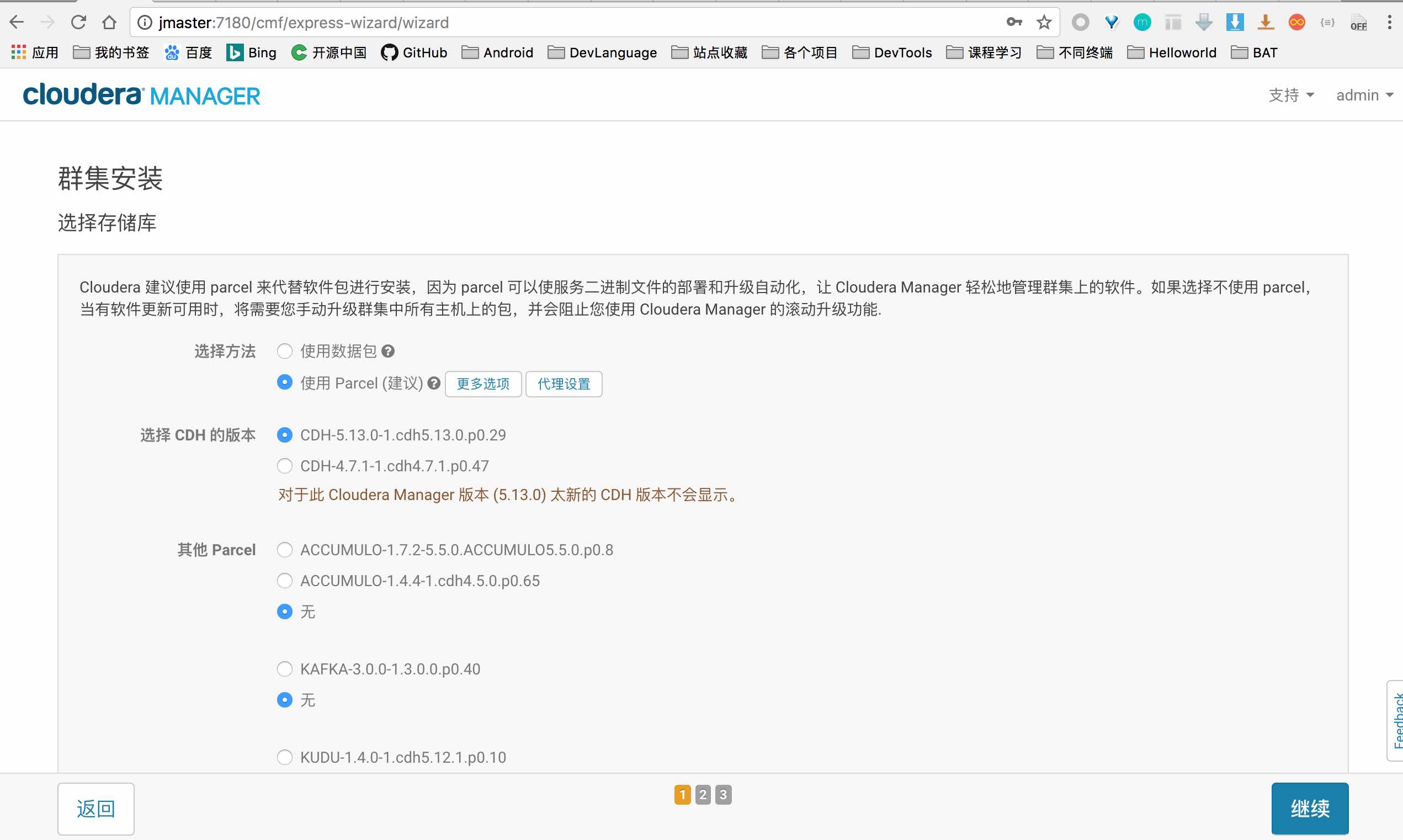
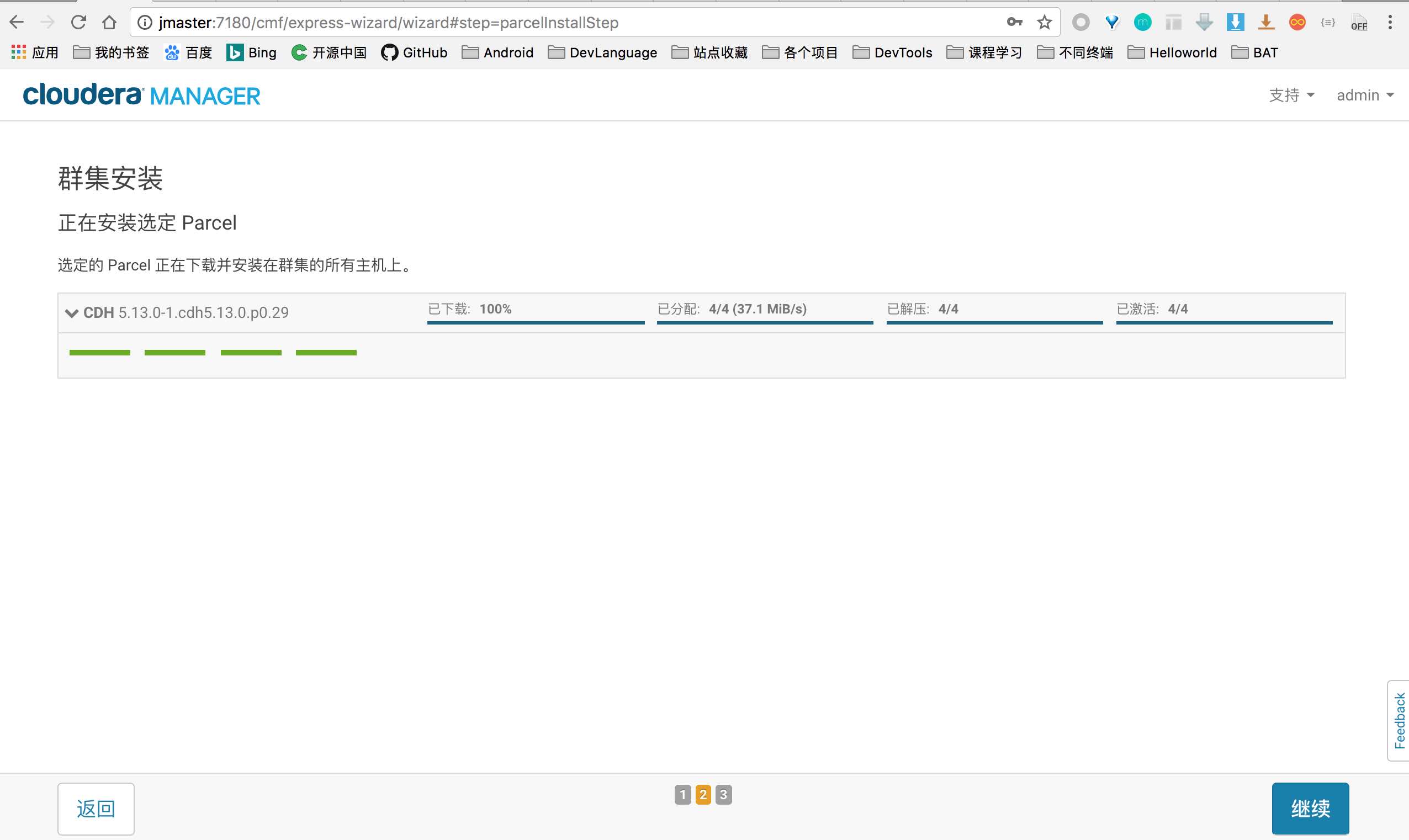
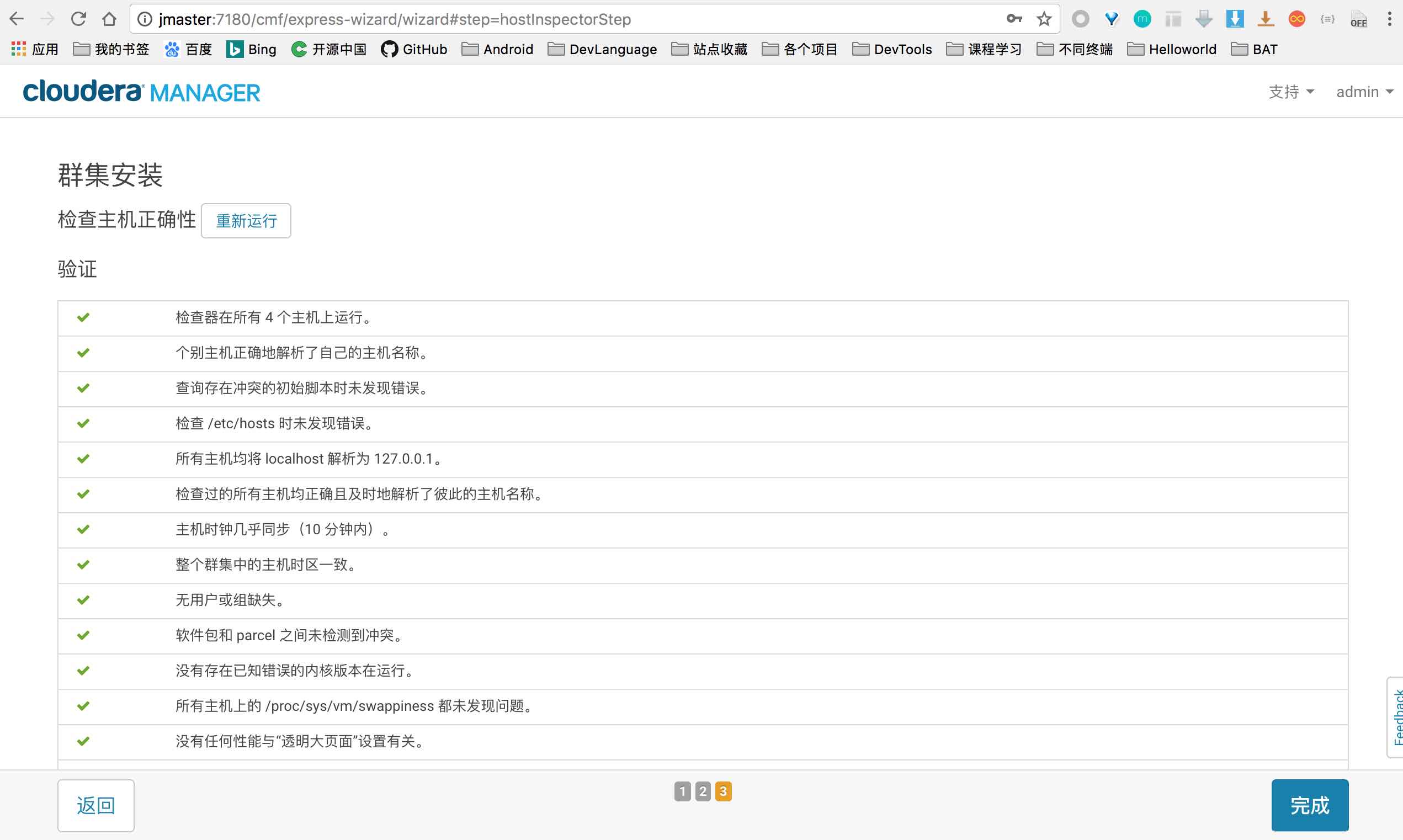
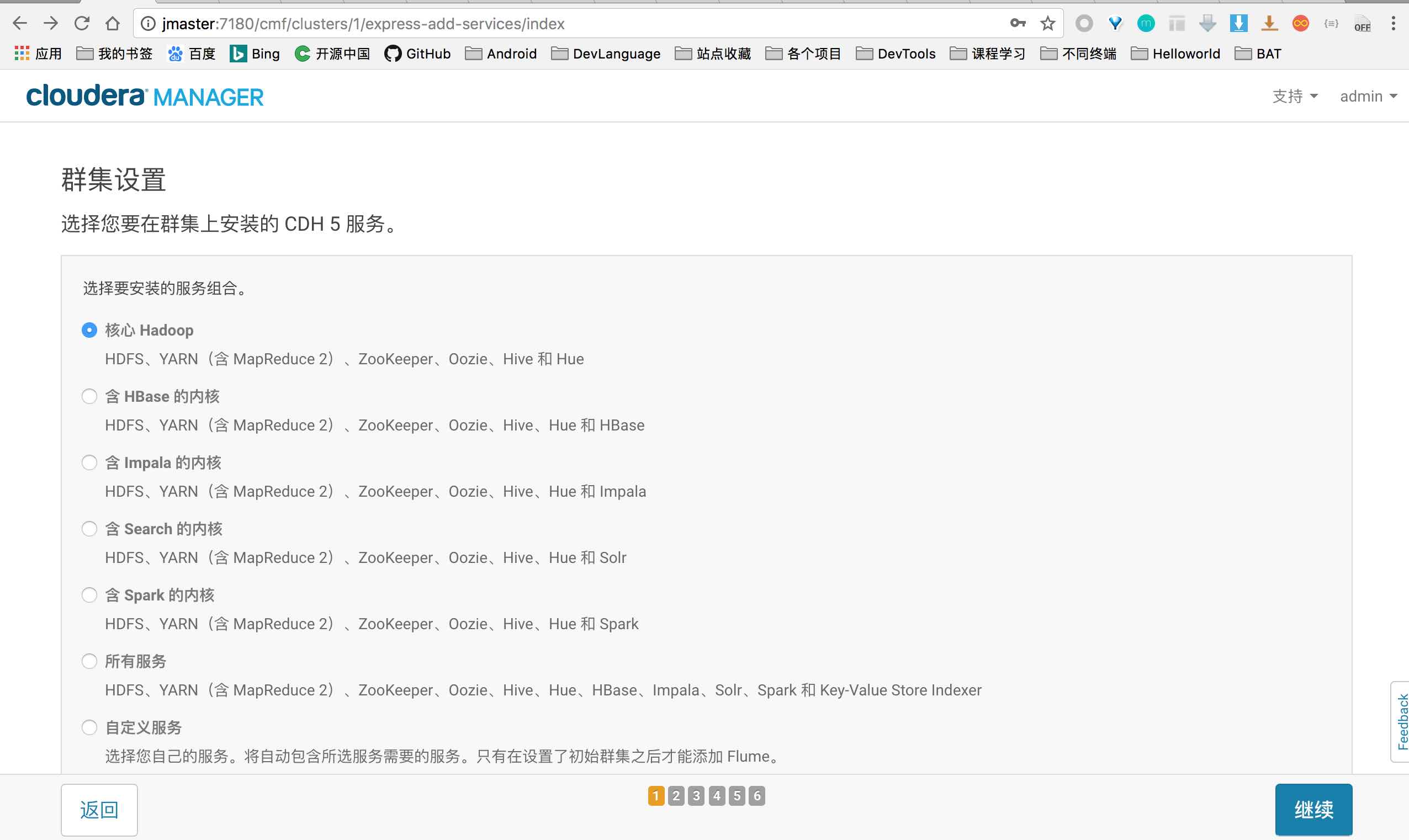
简介
1 . 七十年代末,Donald E. Knuth(高德纳) 在看到其多卷巨著 “The Art of Computer Programming” 第二卷的校样时,对由计算机排版的校样的低质量感到无法忍受。因此决定自己来开发一个高质量的计算机排版系统,这样就有了 TeX 。
2 . TeX 的第一版于 1978 年面世,TeX 的源程序是用 Pascal 写成的,原因是 Knuth 希望 TeX 尽可能方便地移植到其它的操作系统中去。当时 Pascal 是最适合于这一要求的编程语言。这也使得 TeX 现在已经在几乎所有的计算机系统中得到实现。
3 . TeX 的另一个重要的特征就是它的输出是与 设备无关 的。TeX 的输出文件称为 DVI 文件,即是 “Device Independent” 。一旦 TeX 处理了你的文件,你所得到的 DVI 文件就可以被送到任何输出设备如打印机,屏幕等并且总会得到相同的结果,而这与这些输出设备的限制没有任何关系。这说明 DVI 文件中所有的元素,从页面设置到文本中字符的位置都被固定,不能更改。

4 . TeX 现在已经被它的开发者 Knuth 所 “冰封”(frozen),基本不再开发了。但新的变种版本不断出现,
- LaTeX: 1984 年,由 Lamport 开发, 适合论文书籍, 对 TeX 推广贡献巨大,由于其标准的格式控制,latex 逐渐成为主流的 TeX 文档排版命令。LaTeX 时代开启。
- PDFTeX : 1997 年,由 H.T. Thanh 开发,完全兼容标准的 TeX ,但能够给出 PDF 输出。它也可以输出标准的 DVI 。
- XeTeX : 2005年,Jonathan Kew 在 e-TeX 基础上添加 Unicode 支持,并且连接 Mac OS X 的各种技术。XeTeX 在2005/6年陆续发布了它的 Windows 和 Linux 版本,最终集成在 TeXLive 2007 当中,标志着它被广泛地认可。在 XeTeX 中,使用多国语言,变得非常轻松。
- LuaTeX : 2007年,是 Aleph 与 PDFTeX 项目的继任者,主要由 Taco Hoekwater 开发,是 Lua 脚本语言和 TeX 的结合。
5 . LaTex 发型版本:
- TeXLive : 【官方】是由国际 TeX 用户组织 TUG 开发的 TeX 系统,支持不同的操作系统平台。其 Windows 版本又称 fpTeX , Unix/Linux 版本即著名的 teTeX, Mac 版本为 MacTeX。ISO 镜像下载地址:点我
- MiKTeX : 原来是 Windows 系统平台上的一个发行版本,之后也扩展支持到 Linux 和 MacOS 了。其本身集成了一个编辑器 TeXworks。
- CTex : 这个很多人谈论到中文 LaTeX 的时候会提到,但是 CTeX 发行版是民间为早期 LaTeX 不支持中文而基于 MiKTeX 开发的支持中文版本。其本身就是 MiKTeX。但现在 Unicode 支持的 XeTeX 和其他 TeX 已经趋于成熟,因此,现在不推荐再用 CTeX 版本了。
- CTeX 宏集 : 这里要提一下 CTeX 宏集,这个宏集与 CTeX 发行版本/套装 是完全不一样的东西,CTeX 宏集是 Chinese Support TeX,是为支持中文的 TeX 库,这个是在用到中文时必须要用的库,因此,千万不要混淆这两者。现今所说的 CTeX 一般都是指这个 CTeX 宏集。
发行版本
发行版本就是 LaTeX 多种标准实现类型。主要是分为 TeXLive 和 MiKTeX,其他版本都是基于这两个主流版本衍生而来的。这两大发行版本都是全平台支持的。MacTeX 实际上就是 TeXLive 的 MacOS 系统上的实现,因此这里归类其为 TeXLive。相关说明如下:
- TeXLive: https://tug.org/texlive,【官方】发行,自带 TeXShop;
- MacTeX: https://tug.org/mactex, 实际上属于TeXLive,因为支持 MacOS 较迟,因此给了新名称,自带 TeXShop;
- MiKTeX: http://www.miktex.org, 自带 TeXWorks;
CTeX: http://www.ctex.org/HomePage,XeTeX 出现之前民间中文支持的版本,基于 MiKTeX,不再维护。目前中文文档用 XeTeX + CTeX 宏包即可支持了。
如果需要安装的话,大家看官网实际上都能找到地址的,为方便这里列下不同发行版本的不同平台下载地址:
TeXLive
MiKTeX, 这个资源简单,同一个页面选择不同系统即可
- Windows: https://miktex.org/download
- MacOS: https://miktex.org/download
- Linux: https://miktex.org/download
编辑器
LaTeX 实际上和 Java 语言一样,都是需要先配置环境,然后选择一款自己喜欢的编辑器或 IDE 进行编写“代码”。当然所有文本编辑器都可以编写 LaTeX 或者 Java 等其他语言“代码”。这里的 IDE 指集成了一些语言本地化的功能,比如编译、特殊符号等等。
LaTeX 的发行版中会自带一款编辑器,用 TexLive 的话,MacOS 上会有个叫 TexShop 的编辑器,而 Windows 上则会是一个叫 TexWorker 的编辑器,这些是都可以胜任编写工作的。另外,也有第三的 LaTeX 编辑器,下面我整理出所有编辑器说明,我个人用的也推荐程度也放上了,这是个人喜好,大家根据自己的偏好选择。
- TeXMaker: http://www.xm1math.net/texmaker/ , 全平台,免费,强烈推荐👍👍👍;
- TeXStudio: http://texstudio.sourceforge.net/ , 全平台,免费,推荐👍👍;
- WinEdit: http://www.winedt.com/index.html , 只支持 Windows,收费,自己选👍👍🍚;
- TeXWorks: http://www.tug.org/texworks/ ,MiKTeX 自带编辑器,免费👍;
- TeXShop: https://pages.uoregon.edu/koch/texshop/ ,TeXLive 自带编辑器,免费👍;
我个人推荐前两个,因为第三个收费且不跨平台,之所以写上第三个,主要是因为网络上很多博客或用户都推荐用第三个,这个我使用时也感觉不错,但每次我使用都得到 Windows 上使用,比较麻烦。当然,如果你使用 Windows 且有钱,WinEdt 确实使用体验和功能都是比较好的。
安装
- Windows / MacOS: 建议安装 TeXLive,根据自己的系统选择对应的安装包。Mac 系统对应 MacTeX。
MacOS: 安装后会自动将命令加入到环境变量, 并自带 TeXShop 编辑器。
1
2$ which latex
/Library/TeX/texbin/latexMacOS: TeXShop 是 MacTeX 自带的编辑器,我个人倾向于再安装一个编辑器 TeXMaker,其内置较多可视化符号,可点击插入,简单便捷。
- Windows: 推荐 TeXMaker 和 WinEdt , 专门针对 TeX 开发, 提供许多便捷功能, 有助于提高排版效率
编译推荐: 用
pdflatex( 英文文档 ) 或xelatex( 中文文档 ) 编译, 生成相应的 pdf 文件。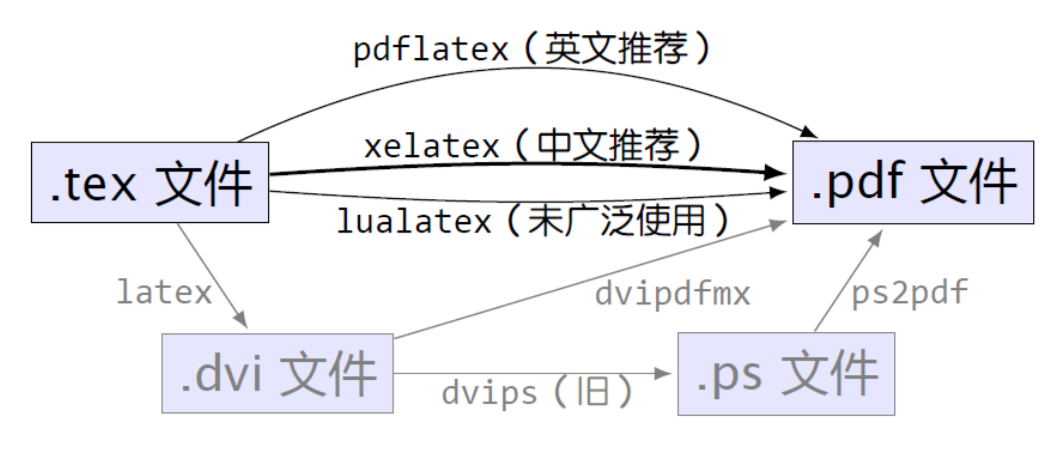
使用
基础框架
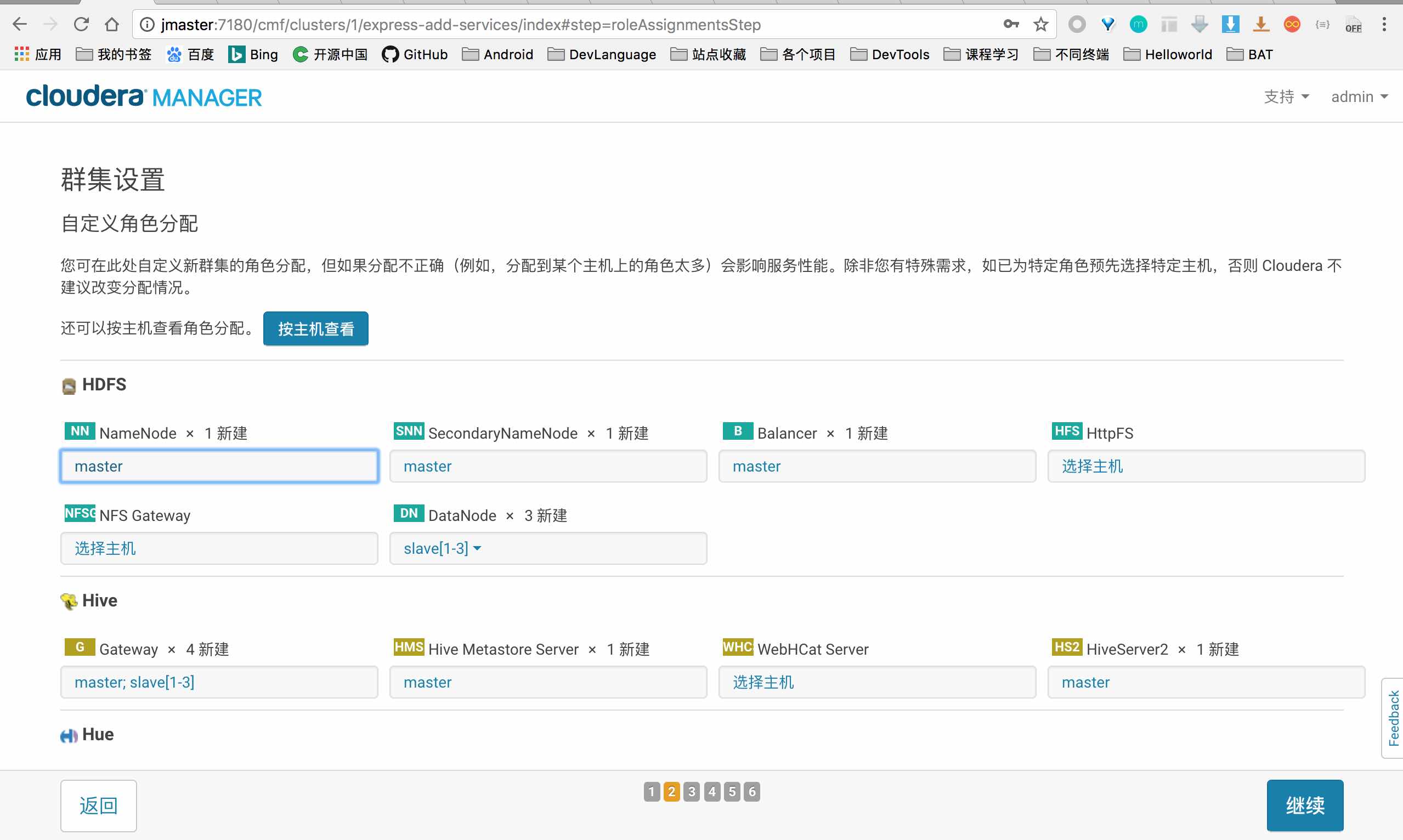
1 . 基本结构
1 | \documentclass[a4paper]{article} % 指定文档类型 |
- LaTeX 源文件:正文 + 命令 + 注解。
- 排版命令(简称:命令):反斜杠 开头的字符串。
- 注解符号:百分号 %
- 文档类型:
\documentclass{...}(论文、书籍、幻灯片、海报) - 环境:
\beigin{...}开头,\end{...}结尾。 - 附:
\documentclass[]{}就是引用模板,默认提供 article 等模板。
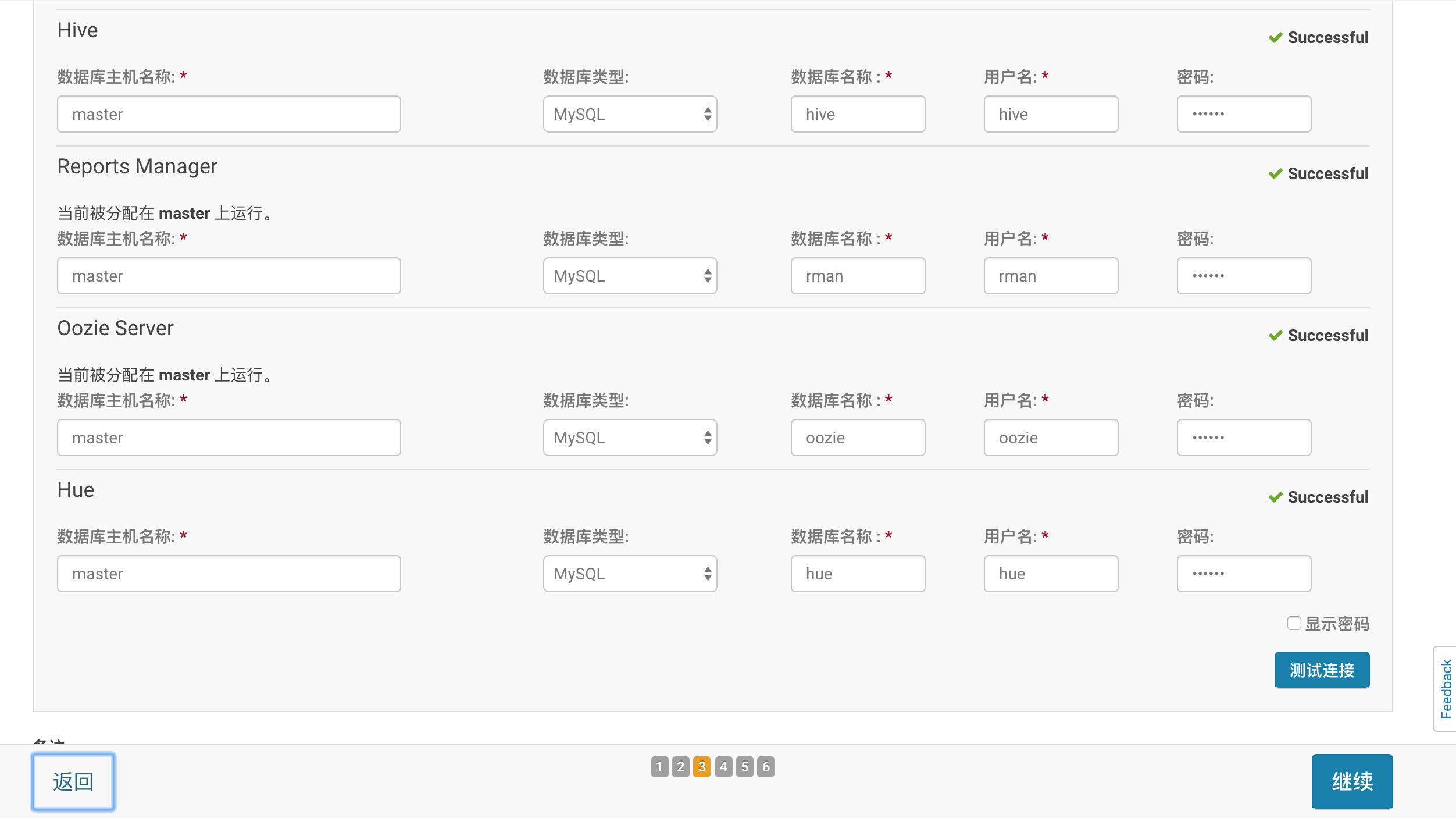
2 . 排版命令
方括号中的是可选的 (称为选项), 花括号中的参数是必需的
1
2
3
4
5\command
\command[option]{arguments}
% 一些常用命令:
\documentcalss, \title, \author, \date, \usepackage
\begin{环境名}, \end{环境名} % 组成一个环境定义新命令
1
2
3
4\newcommand{新命令}{命令内容}
\renewcommand{已有命令}{命令内容}
% 举例
\newcommand{\eps}{\varepsilon} % $\eps$ → ε文档类型:
\documentclass[选项]{文档类}- 位于源文件的最前面, 用于指定文档的整体结构和布局, 必须且只能选一种
- 常用 文档类: article, book, beamer, ctexart, ctexbook, ctexbeamer
- 常用 选项:
- 10pt(缺省值), 11pt, 12pt → 指定基本字体的大小
- letterpaper(缺省值), a4paper, a5paper, … → 指定纸张的大小
- 单双面选项: oneside, twoside, openright, openany
- 数学公式: leqno (公式编号在左边), fleqn (靠左显示行间公式)
- 导言区: \documentclass 和 \begin{document} 之间的区域
- 导言区用于放置 全局控制命令, 如: 调用宏包, 设置页面大小, …
- 放在导言区的命令对整个文档都起作用
- 位于源文件的最前面, 用于指定文档的整体结构和布局, 必须且只能选一种
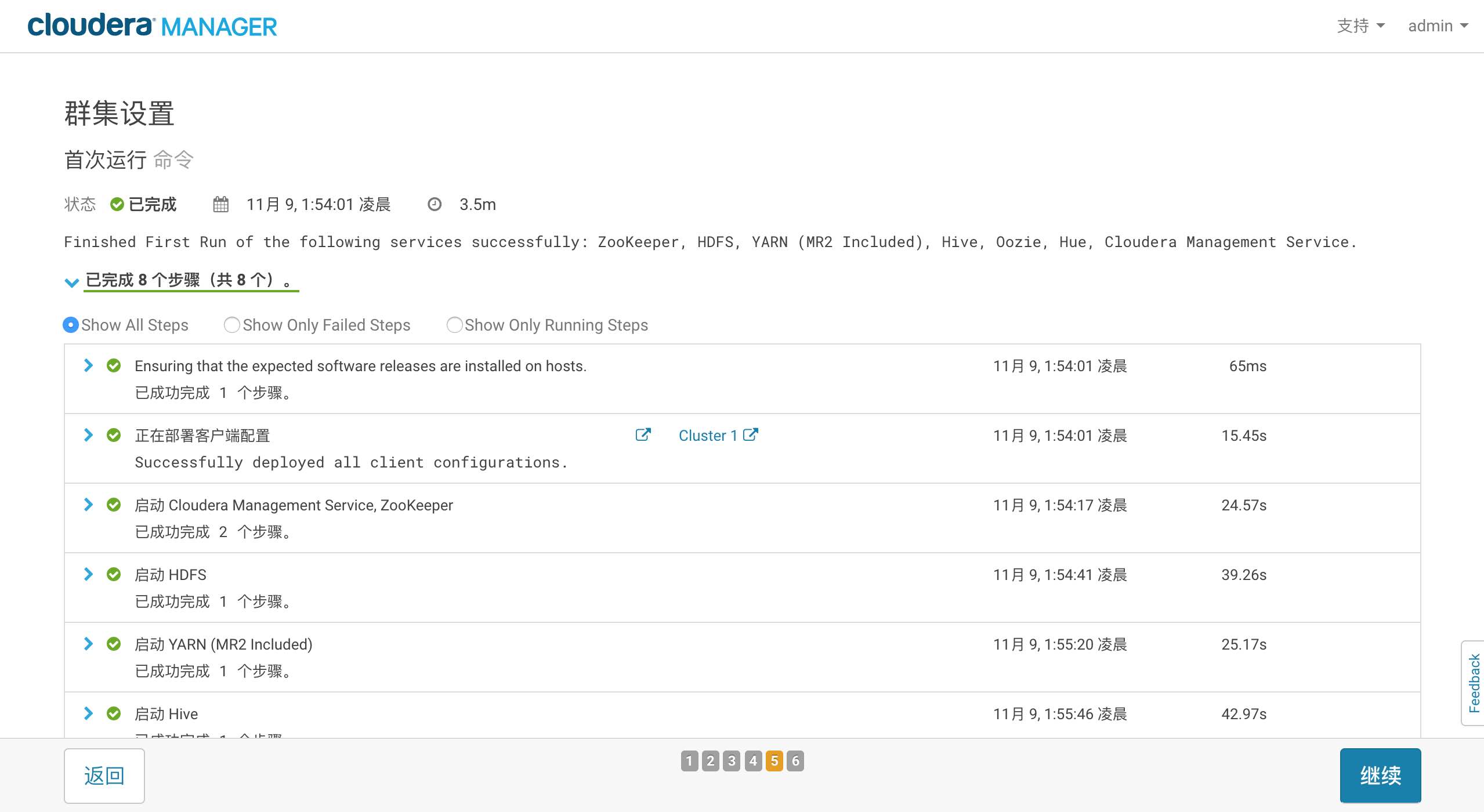
3 . 中文排版
- CTEX 宏集中提供了三个中文文档类: texart, ctexbook, ctexbeamer
用
xelatex编译! 用 xelatex 编译! 用 xelatex 编译!1
2
3
4
5
6
7
8
9
10\documentclass[12pt,a4paper]{ctexart}
\usepackage{amsmath} % AMS 数学公式 宏包
\usepackage{amssymb} % AMS 数学符号 宏包
\usepackage{amsfonts} % AMS 数学字体 宏包
\usepackage{graphicx} % 插图 宏包
\usepackage{xcolor} % 彩色 宏包
\begin{document}
欧拉公式是
$$ e^{ix} = \cos(x) + i\sin(x).$$
\end{document}
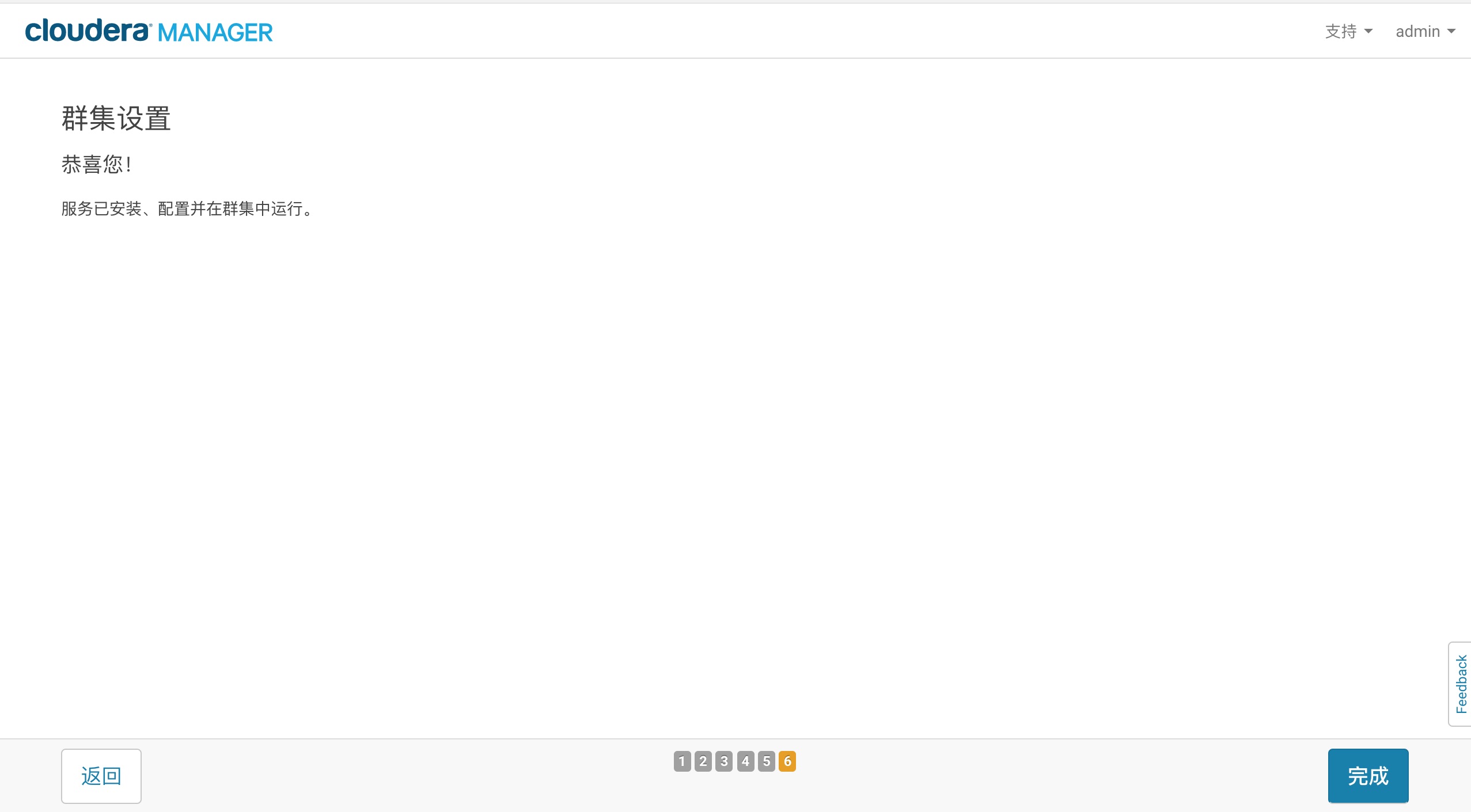
常用包和命令
1 . 代码和注释:
1 | % 页面布局:页面宽度, 页面高度, 页眉高度, 页脚高度,各种边距等等 |
2 . 特殊说明
- 短标题: 用于显示在目录和页眉中, 缺省与标题相同
带星号的章节命令: 不参与自动编号
1
2\章节命令[短标题]{标题}
\章节命令*{标题}章节举例

文本对齐方式 (缺省为左对齐)
- 左对齐:
\raggedright或使用flushleft环境 - 右对齐:
\raggedleft或使用flushright环境 - 文本居中:
\centering或使用center环境
- 左对齐:
字体大小
英文/中文都适用
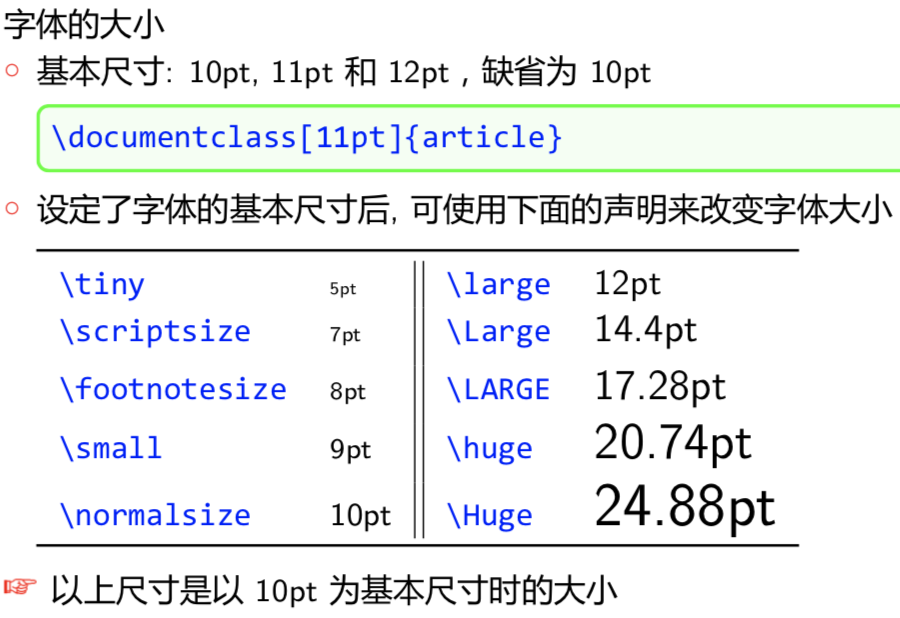
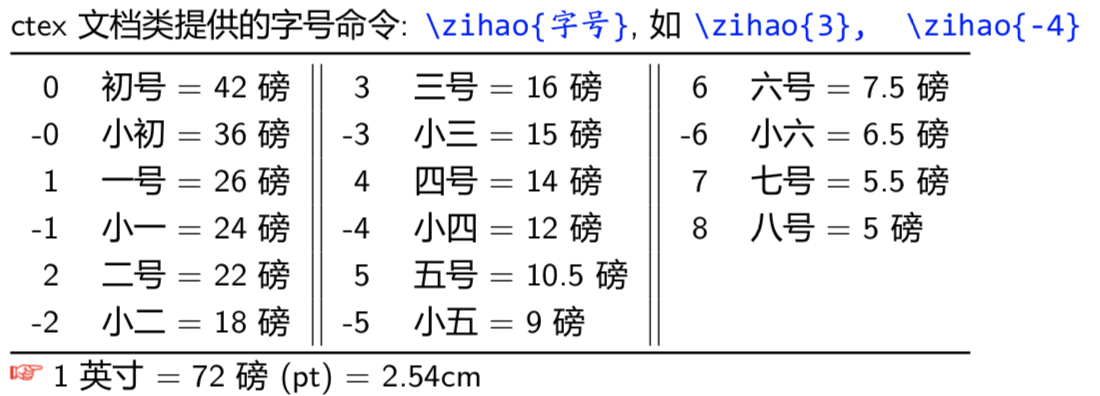
中文字体:
ctex提供的命令和字号命令如下1
\heiti, \songti, \fangsong, \kaishu, \lishu, \youyuan, \yahei
超链接
1 . \usepackage[选项列表]{hyperref}
- 在有交叉引用的地方 (如目录, 书签, 参考文献, 公式等) 建立链接
- 提供对外部文件, 互联网网址, 邮件地址的链接
- 常用选项 (也可通过
\hypersetup{选项列表}来设置)bookmarks→ 创建书签, 缺省为 trueCJKbookmarks→ 支持中日韩文字的书签colorlinks→ 使用彩色显示链接, 缺省为红色方框linkcolor→ 内部普通链接 (如页码) 的颜色, 缺省为 redcitecolor→ 文献引用链接的颜色, 缺省为 greenurlcolor→ URL 链接的颜色, 缺省为 magentabreaklinks→ 允许在链接中断行, 缺省不允许
2 . 例子:
1 | \usepackage{hyperref} |
3 . 创建网页链接: \url 和 \href
1 | \url{网址} |
\url→ 生成 网址 的同时在页面上输出其内容\href→ 生成 网址 的同时在页面上输出 文本 的内容
颜色
1 | \documentclass{article} |
相关资源
- LaTeX 工作室 : http://www.latexstudio.net (模板、方法、教程)
- LaTeX 模板收集 : http://www.latextemplates.com (各种模板)
- LaTeX 颜色定义 : http://latexcolor.com
- 华东师大 LaTeX 官网 : http://math.ecnu.edu.cn/~latex (丰富教学资源)
- 华东师大–潘建瑜 : http://math.ecnu.edu.cn/~jypan/Teaching/Latex (各种分享、教程、资料) 👍👍👍
- 本文很多截图来源于 潘建瑜 PPT 中。
- 武汉大学–黄正华 : http://aff.whu.edu.cn/huangzh (各种教学资料)
- [英] LaTeX 使用技巧 : http://latex-cookbook.net
- [英] TeX Users Group : http://www.tug.org
- [英] LaTeX Packages : https://www.ctan.org